Abstract
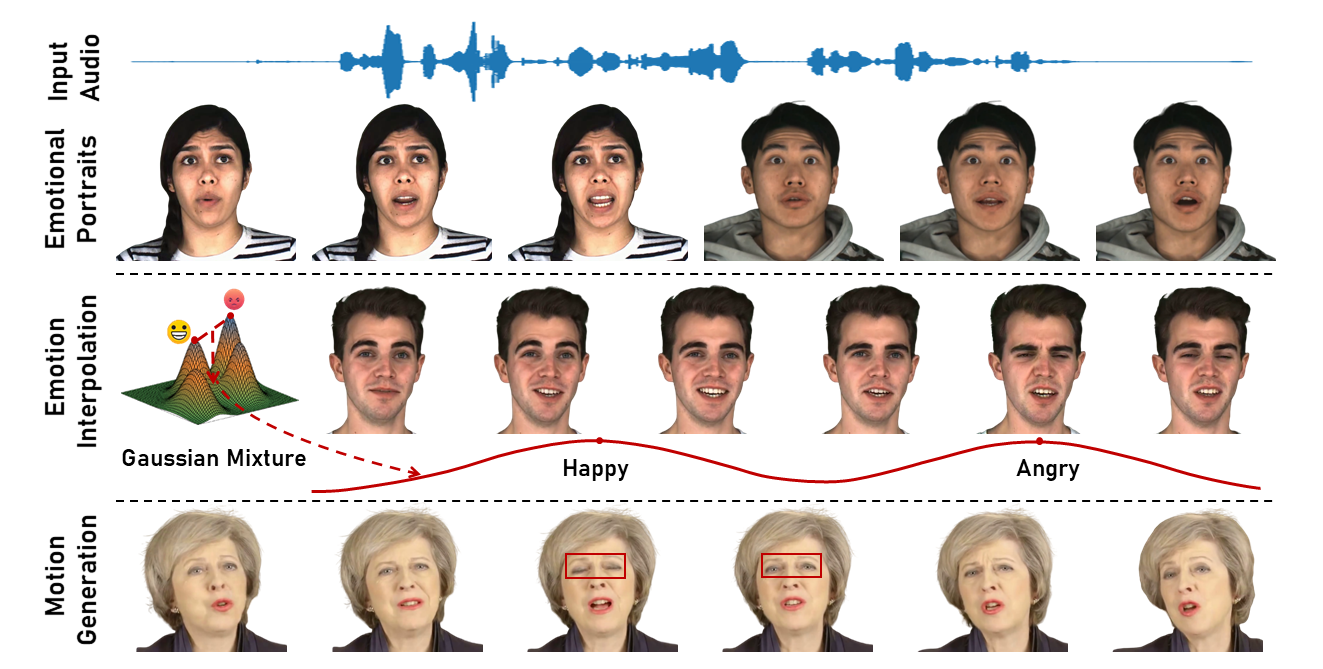
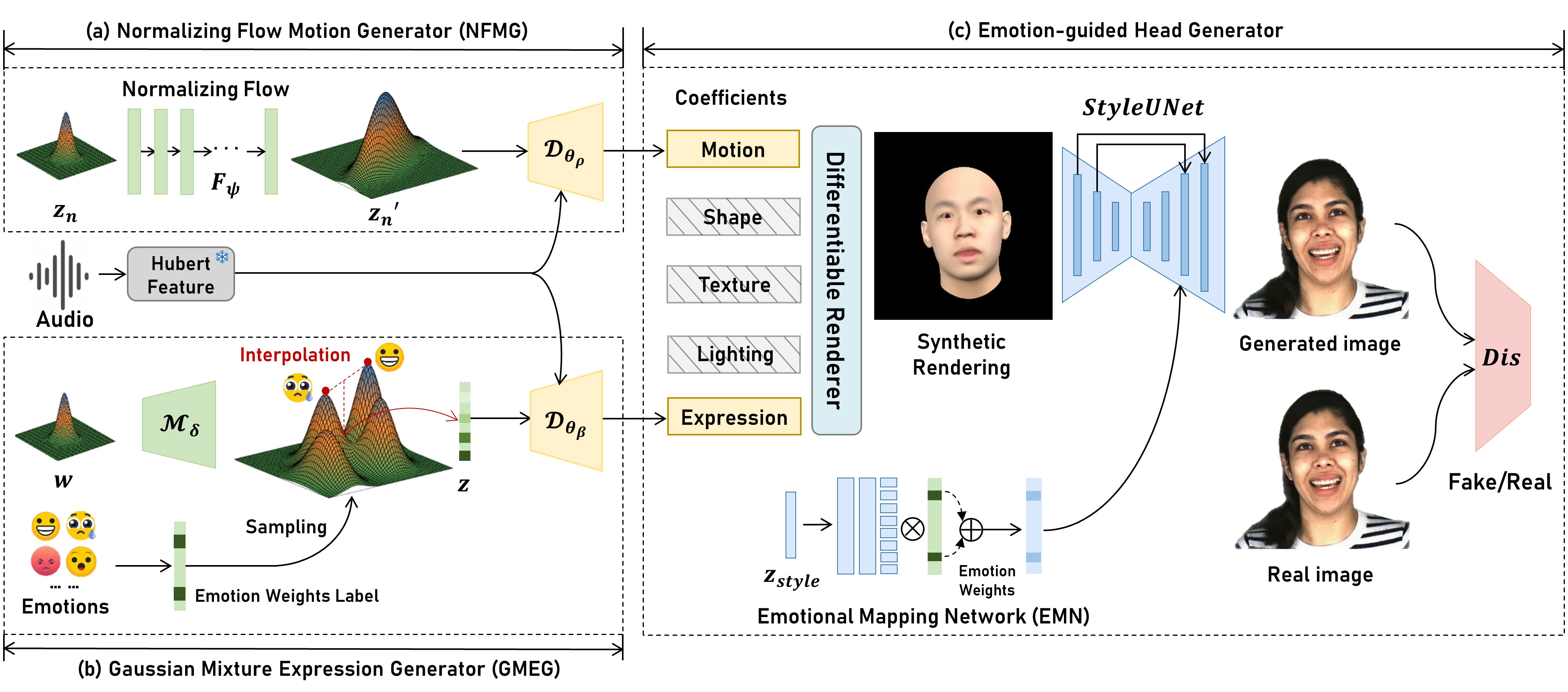
Synthesizing high-fidelity and emotion-controllable talking video portraits, with audio-lip sync, vivid expressions, realistic head poses, and eye blinks, has been an important and challenging task in recent years. Most existing methods suffer in achieving personalized and precise emotion control, smooth transitions between different emotion states, and the generation of diverse motions. To tackle these challenges, we present GMTalker, a Gaussian mixture-based emotional talking portraits generation framework. Specifically, we propose a Gaussian mixture-based expression generator that can construct a continuous and disentangled latent space, achieving more flexible emotion manipulation. Furthermore, we introduce a normalizing flow-based motion generator pretrained on a large dataset with a wide-range motion to generate diverse head poses, blinks, and eyeball movements. Finally, we propose a personalized emotion-guided head generator with an emotion mapping network that can synthesize high-fidelity and faithful emotional video portraits. Both quantitative and qualitative experiments demonstrate our method outperforms previous methods in image quality, photo-realism, emotion accuracy, and motion diversity.